Cluster Computing: Definition and Architecture of a Cluster
What is a Cluster ?
 In its most basic form, a cluster is a system comprising two or more computers or systems (called nodes) which work together to execute applications or perform other tasks, so that users who use them, have the impression that only a single system responds to them, thus creating an illusion of a single resource (virtual machine). This concept is called transparency of the system. As key features for the construction of these platforms is included elevation : reliability, load balancing and performance.
Types of Clusters
High Availability (HA) and failover clusters, these models are built to provide an availability of services and resources in an uninterrupted manner through the use of implicit redundancy to the system. The general idea is that if a cluster node fail (failover), applications or services may be available in another node. These types are used to cluster data base of critical missions, mail, file and application servers.
Load balancing, this model distributes incoming traffic or requests for resources from nodes that run the same programs between machines that make up the cluster. All nodes are responsible to track orders. If a node fails, the requests are redistributed among the nodes available. This type of solution is usually used on farms of Web servers (web farm).
HA & Load Balancing Combination, as its name says, it combines the features of both types of cluster, thereby increasing the availability and scalability of services and resources. This type of cluster configuration is widely used in web, email, news, or ftp servers.
Distributed Processing and Parallel Processing, this cluster model improves the availability and performance for applications, particularly large computational tasks. A large computational task can be divided into smaller tasks that are distributed around the stations (nodes), like a massively parallel supercomputer. It is common to associate this type of Beowulf cluster at NASA project. These clusters are used for scientific computing or financial analysis, typical for tasks requiring high processing power.
Reasons to Use a Cluster
Clusters or combination of clusters are used when content is critical or when services have to be available and / or processed as quickly as possible. Internet Service Providers (ISPs) or e-commerce sites often require high availability and load balancing in a scalable manner. The parallel clusters are heavily involved in the film industry for rendering high quality graphics and animations, recalling that the Titanic was rendered within this platform in the Digital Domain laboratories. The Beowulf clusters are used in science, engineering and finance to work on projects of protein folding, fluid dynamics, neural networks, genetic analysis, statistics, economics, astrophysics among others. Researchers, organizations and companies are using clusters because they need to increase their scalability, resource management, availability or processing to supercomputing at an affordable price level.
In its most basic form, a cluster is a system comprising two or more computers or systems (called nodes) which work together to execute applications or perform other tasks, so that users who use them, have the impression that only a single system responds to them, thus creating an illusion of a single resource (virtual machine). This concept is called transparency of the system. As key features for the construction of these platforms is included elevation : reliability, load balancing and performance.
Types of Clusters
High Availability (HA) and failover clusters, these models are built to provide an availability of services and resources in an uninterrupted manner through the use of implicit redundancy to the system. The general idea is that if a cluster node fail (failover), applications or services may be available in another node. These types are used to cluster data base of critical missions, mail, file and application servers.
Load balancing, this model distributes incoming traffic or requests for resources from nodes that run the same programs between machines that make up the cluster. All nodes are responsible to track orders. If a node fails, the requests are redistributed among the nodes available. This type of solution is usually used on farms of Web servers (web farm).
HA & Load Balancing Combination, as its name says, it combines the features of both types of cluster, thereby increasing the availability and scalability of services and resources. This type of cluster configuration is widely used in web, email, news, or ftp servers.
Distributed Processing and Parallel Processing, this cluster model improves the availability and performance for applications, particularly large computational tasks. A large computational task can be divided into smaller tasks that are distributed around the stations (nodes), like a massively parallel supercomputer. It is common to associate this type of Beowulf cluster at NASA project. These clusters are used for scientific computing or financial analysis, typical for tasks requiring high processing power.
Reasons to Use a Cluster
Clusters or combination of clusters are used when content is critical or when services have to be available and / or processed as quickly as possible. Internet Service Providers (ISPs) or e-commerce sites often require high availability and load balancing in a scalable manner. The parallel clusters are heavily involved in the film industry for rendering high quality graphics and animations, recalling that the Titanic was rendered within this platform in the Digital Domain laboratories. The Beowulf clusters are used in science, engineering and finance to work on projects of protein folding, fluid dynamics, neural networks, genetic analysis, statistics, economics, astrophysics among others. Researchers, organizations and companies are using clusters because they need to increase their scalability, resource management, availability or processing to supercomputing at an affordable price level.
 High-Availability (HA) or Clusters Failover
The computers have a strong tendency to stop when you least expect, especially at a time when you need it most. It is rare to find an administrator who never received a phone call in the middle of the morning with the sad news that the system was down, and you have to go and fix the problem.
High Availability is linked directly to our growing dependence on computers, because now they have a critical role primarily in companies whose main functionality is exactly the offer of some computing service, such as e-business, news, web sites, databases, among others.
A High Availability Cluster aims to maintain the availability of services provided by a computer system by replicating servers and services through redundant hardware and software reconfiguration. Several computers acting together as one, each one monitoring the others and taking their services if any of them will fail. The complexity of the system must be software that should bother to monitor other machines on a network, know what services are running, those who are running, and what to do in case of a failure. Loss in performance or processing power are usually acceptable, the main goal is not to stop. There are some exceptions, like real-time and mission critical systems.
Fault tolerance is achieved through hardware like raid systems, supplies and redundant boards, fully connected network systems to provide alternative paths in the breaking of a link.
Cluster Load Balancing
The load balancing among servers is part of a comprehensive solution in an explosive and increasing use of network and Internet. Providing an increased network capacity, improving performance. A consistent load balancing is shown today as part of the entire Web Hosting and eCommerce project. But you cannot get stuck with the ideas that it is only for providers, we should take their features and bring into the enterprise this way of using technology to heed internal business customers.
The cluster systems based on load balancing integrate their nodes so that all requests from clients are distributed evenly across the nodes. The systems do not work together in a single process but redirecting requests independently as they arrive based on a scheduler and an algorithm.
This type of cluster is specially used by e-commerce and Internet service providers who need to resolve differences cargo from multiple input requests in real time.
Additionally, for a cluster to be scalable, must ensure that each server is fully utilized.
When we do load balancing between servers that have the same ability to respond to a client, we started having problems because one or more servers can respond to requests made and communication is impaired. So we put the element that will make balancing between servers and users, and configure it to do so, however we can put multiple servers on one side that, for the customers, they appear to be only one address. A classic example would be the Linux Virtual Server, or simply prepare a DNS load balancer. The element of balance will have an address, where customers try to make contact, called Virtual Server ( VS ), which redirects traffic to a server in the server pool. This element should be a software dedicated to doing all this management, or may be a network device that combines hardware performance and software to make the passage of the packages and load balancing in a single device.
We highlight some key points for an implementation in an environment of success with load balancing on the powerful dedicated servers:
The algorithm used for load balancing, taking into consideration how balancing between servers is done and when a client makes a request to the virtual address ( VS ), the whole process of choosing the server and the server response must occur transparent and imperceptible to the user mode as if no balancing.
Create a method to check if the servers are alive and working, vital if the communication is not redirected to a server that has just had a failure (keepalive).
A method used to make sure that a client accessing the same server when you want.
Load balancing is more than a simple redirect client traffic to other servers. For proper implementation, the equipment you will need to have balancing characteristics as permanent communication check, verification of servers and redundancy. All of these items are necessary to support the scalability of the volume of traffic on the networks without eventually become a bottleneck or single point of failure.
Algorithms for balancing is one of the most important factors in this context, then we will explain three basic methods :
Least Connections
This technique redirects the requests to the lowest based on the number of requests / server connections. For example, if server 1 is currently handling 50 requests / connections, and server 2 controls 25 requests / connections, the next request / connection will be automatically directed to the second server, since the server currently has fewer requests / connections active.
Round Robin
This method uses the technique of always direct requests to the next available server in a circular fashion. For example, incoming connections are directed to the server 1, server 2 and then finally server 3 and then the server 1 returns.
Weighted Fair
This technique directs the requests to the load based on the requests of each and the responsiveness of the same (performance) For example, if the servers server 1 is four times faster in servicing requests from the server 2, the administrator places a greater burden of work for the server 1 to server 2.
Combined Cluster High Availability and Load Balancing
This combined solution aims to provide a high performance solution combined with the possibility of not having critical stops. This combined cluster is a perfect solution for ISPs and network applications where continuity of operations is very critical.
Some features of this platform :
High-Availability (HA) or Clusters Failover
The computers have a strong tendency to stop when you least expect, especially at a time when you need it most. It is rare to find an administrator who never received a phone call in the middle of the morning with the sad news that the system was down, and you have to go and fix the problem.
High Availability is linked directly to our growing dependence on computers, because now they have a critical role primarily in companies whose main functionality is exactly the offer of some computing service, such as e-business, news, web sites, databases, among others.
A High Availability Cluster aims to maintain the availability of services provided by a computer system by replicating servers and services through redundant hardware and software reconfiguration. Several computers acting together as one, each one monitoring the others and taking their services if any of them will fail. The complexity of the system must be software that should bother to monitor other machines on a network, know what services are running, those who are running, and what to do in case of a failure. Loss in performance or processing power are usually acceptable, the main goal is not to stop. There are some exceptions, like real-time and mission critical systems.
Fault tolerance is achieved through hardware like raid systems, supplies and redundant boards, fully connected network systems to provide alternative paths in the breaking of a link.
Cluster Load Balancing
The load balancing among servers is part of a comprehensive solution in an explosive and increasing use of network and Internet. Providing an increased network capacity, improving performance. A consistent load balancing is shown today as part of the entire Web Hosting and eCommerce project. But you cannot get stuck with the ideas that it is only for providers, we should take their features and bring into the enterprise this way of using technology to heed internal business customers.
The cluster systems based on load balancing integrate their nodes so that all requests from clients are distributed evenly across the nodes. The systems do not work together in a single process but redirecting requests independently as they arrive based on a scheduler and an algorithm.
This type of cluster is specially used by e-commerce and Internet service providers who need to resolve differences cargo from multiple input requests in real time.
Additionally, for a cluster to be scalable, must ensure that each server is fully utilized.
When we do load balancing between servers that have the same ability to respond to a client, we started having problems because one or more servers can respond to requests made and communication is impaired. So we put the element that will make balancing between servers and users, and configure it to do so, however we can put multiple servers on one side that, for the customers, they appear to be only one address. A classic example would be the Linux Virtual Server, or simply prepare a DNS load balancer. The element of balance will have an address, where customers try to make contact, called Virtual Server ( VS ), which redirects traffic to a server in the server pool. This element should be a software dedicated to doing all this management, or may be a network device that combines hardware performance and software to make the passage of the packages and load balancing in a single device.
We highlight some key points for an implementation in an environment of success with load balancing on the powerful dedicated servers:
The algorithm used for load balancing, taking into consideration how balancing between servers is done and when a client makes a request to the virtual address ( VS ), the whole process of choosing the server and the server response must occur transparent and imperceptible to the user mode as if no balancing.
Create a method to check if the servers are alive and working, vital if the communication is not redirected to a server that has just had a failure (keepalive).
A method used to make sure that a client accessing the same server when you want.
Load balancing is more than a simple redirect client traffic to other servers. For proper implementation, the equipment you will need to have balancing characteristics as permanent communication check, verification of servers and redundancy. All of these items are necessary to support the scalability of the volume of traffic on the networks without eventually become a bottleneck or single point of failure.
Algorithms for balancing is one of the most important factors in this context, then we will explain three basic methods :
Least Connections
This technique redirects the requests to the lowest based on the number of requests / server connections. For example, if server 1 is currently handling 50 requests / connections, and server 2 controls 25 requests / connections, the next request / connection will be automatically directed to the second server, since the server currently has fewer requests / connections active.
Round Robin
This method uses the technique of always direct requests to the next available server in a circular fashion. For example, incoming connections are directed to the server 1, server 2 and then finally server 3 and then the server 1 returns.
Weighted Fair
This technique directs the requests to the load based on the requests of each and the responsiveness of the same (performance) For example, if the servers server 1 is four times faster in servicing requests from the server 2, the administrator places a greater burden of work for the server 1 to server 2.
Combined Cluster High Availability and Load Balancing
This combined solution aims to provide a high performance solution combined with the possibility of not having critical stops. This combined cluster is a perfect solution for ISPs and network applications where continuity of operations is very critical.
Some features of this platform :
- Redirection of requests to node failures reservations for us ;
- Improved quality of service levels for typical network applications ;
- Transparent integration for stand-alone applications and non-clustered together in a single virtual network ;
- Provide a highly scalable architecture framework.
What is a Beowulf Cluster ?
One of the most remarkable technological advances of today, has been the growth of the computational performance of PCs (Personal Computers). The truth is that the PC market is larger than the market for workstations, allowing the decrease in price of a PC, while its performance increases substantially overlapping in many cases, the performance of dedicated workstations.
The Beowulf cluster was envisioned by its developers in order to meet the growing and high processing power in various scientific areas in order to build powerful and affordable cloud computing systems. Of course the constant evolution of processor performance, and has collaborated in approach between PCs and Workstations, decreasing costs of network processors and own technologies and open free operating system like GNU / Linux much research to influence improvement of this new philosophy of high performance processing in clusters.
A key feature of a Beowulf cluster, the software is used, which is of high performance and complimentary on most of their tools, as an example we can mention GNU / Linux and FreeBSD operating systems which are installed on the various tools that enable processing parallel, as is the case of PVM and MPI API’s. This allow to make changes to the Linux operating system to provide it with new features that facilitated the implementation for parallel applications.
Works like Beowulf ?
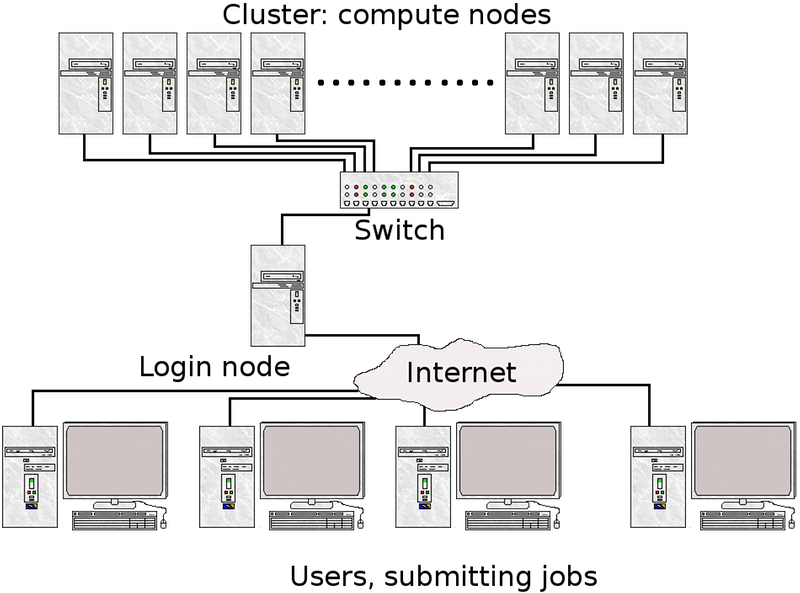
The system is divided into a controller node called front-end (particularly I call the master node), whose function is to control the cluster, monitoring and distributing tasks, acts as a file server and runs the link between users and the cluster. Large clustered systems can deliver several file servers, the network node manages not to overwhelm the system. The other nodes are referred to as customers or backends (well I call slave nodes), and are solely dedicated to processing tasks sent by the controller node, and there is no need for keyboards and monitors, and possibly even without the use of hard drives (remote) boot, and can be accessed via remote login (telnet or ssh).

What is a Cluster ?
In its most basic form, a cluster is a system comprising two or more computers or systems (called nodes) which work together to execute applications or perform other tasks, so that users who use them, have the impression that only a single system responds to them, thus creating an illusion of a single resource (virtual machine). This concept is called transparency of the system. As key features for the construction of these platforms is included elevation : reliability, load balancing and performance.
Types of Clusters
High Availability (HA) and failover clusters, these models are built to provide an availability of services and resources in an uninterrupted manner through the use of implicit redundancy to the system. The general idea is that if a cluster node fail (failover), applications or services may be available in another node. These types are used to cluster data base of critical missions, mail, file and application servers.
Load balancing, this model distributes incoming traffic or requests for resources from nodes that run the same programs between machines that make up the cluster. All nodes are responsible to track orders. If a node fails, the requests are redistributed among the nodes available. This type of solution is usually used on farms of Web servers (web farm).
HA & Load Balancing Combination, as its name says, it combines the features of both types of cluster, thereby increasing the availability and scalability of services and resources. This type of cluster configuration is widely used in web, email, news, or ftp servers.
Distributed Processing and Parallel Processing, this cluster model improves the availability and performance for applications, particularly large computational tasks. A large computational task can be divided into smaller tasks that are distributed around the stations (nodes), like a massively parallel supercomputer. It is common to associate this type of Beowulf cluster at NASA project. These clusters are used for scientific computing or financial analysis, typical for tasks requiring high processing power.
Reasons to Use a Cluster
Clusters or combination of clusters are used when content is critical or when services have to be available and / or processed as quickly as possible. Internet Service Providers (ISPs) or e-commerce sites often require high availability and load balancing in a scalable manner. The parallel clusters are heavily involved in the film industry for rendering high quality graphics and animations, recalling that the Titanic was rendered within this platform in the Digital Domain laboratories. The Beowulf clusters are used in science, engineering and finance to work on projects of protein folding, fluid dynamics, neural networks, genetic analysis, statistics, economics, astrophysics among others. Researchers, organizations and companies are using clusters because they need to increase their scalability, resource management, availability or processing to supercomputing at an affordable price level.
High-Availability (HA) or Clusters Failover
The computers have a strong tendency to stop when you least expect, especially at a time when you need it most. It is rare to find an administrator who never received a phone call in the middle of the morning with the sad news that the system was down, and you have to go and fix the problem.
High Availability is linked directly to our growing dependence on computers, because now they have a critical role primarily in companies whose main functionality is exactly the offer of some computing service, such as e-business, news, web sites, databases, among others.
A High Availability Cluster aims to maintain the availability of services provided by a computer system by replicating servers and services through redundant hardware and software reconfiguration. Several computers acting together as one, each one monitoring the others and taking their services if any of them will fail. The complexity of the system must be software that should bother to monitor other machines on a network, know what services are running, those who are running, and what to do in case of a failure. Loss in performance or processing power are usually acceptable, the main goal is not to stop. There are some exceptions, like real-time and mission critical systems.
Fault tolerance is achieved through hardware like raid systems, supplies and redundant boards, fully connected network systems to provide alternative paths in the breaking of a link.
Cluster Load Balancing
The load balancing among servers is part of a comprehensive solution in an explosive and increasing use of network and Internet. Providing an increased network capacity, improving performance. A consistent load balancing is shown today as part of the entire Web Hosting and eCommerce project. But you cannot get stuck with the ideas that it is only for providers, we should take their features and bring into the enterprise this way of using technology to heed internal business customers.
The cluster systems based on load balancing integrate their nodes so that all requests from clients are distributed evenly across the nodes. The systems do not work together in a single process but redirecting requests independently as they arrive based on a scheduler and an algorithm.
This type of cluster is specially used by e-commerce and Internet service providers who need to resolve differences cargo from multiple input requests in real time.
Additionally, for a cluster to be scalable, must ensure that each server is fully utilized.
When we do load balancing between servers that have the same ability to respond to a client, we started having problems because one or more servers can respond to requests made and communication is impaired. So we put the element that will make balancing between servers and users, and configure it to do so, however we can put multiple servers on one side that, for the customers, they appear to be only one address. A classic example would be the Linux Virtual Server, or simply prepare a DNS load balancer. The element of balance will have an address, where customers try to make contact, called Virtual Server ( VS ), which redirects traffic to a server in the server pool. This element should be a software dedicated to doing all this management, or may be a network device that combines hardware performance and software to make the passage of the packages and load balancing in a single device.
We highlight some key points for an implementation in an environment of success with load balancing on the powerful dedicated servers:
The algorithm used for load balancing, taking into consideration how balancing between servers is done and when a client makes a request to the virtual address ( VS ), the whole process of choosing the server and the server response must occur transparent and imperceptible to the user mode as if no balancing.
Create a method to check if the servers are alive and working, vital if the communication is not redirected to a server that has just had a failure (keepalive).
A method used to make sure that a client accessing the same server when you want.
Load balancing is more than a simple redirect client traffic to other servers. For proper implementation, the equipment you will need to have balancing characteristics as permanent communication check, verification of servers and redundancy. All of these items are necessary to support the scalability of the volume of traffic on the networks without eventually become a bottleneck or single point of failure.
Algorithms for balancing is one of the most important factors in this context, then we will explain three basic methods :
Least Connections
This technique redirects the requests to the lowest based on the number of requests / server connections. For example, if server 1 is currently handling 50 requests / connections, and server 2 controls 25 requests / connections, the next request / connection will be automatically directed to the second server, since the server currently has fewer requests / connections active.
Round Robin
This method uses the technique of always direct requests to the next available server in a circular fashion. For example, incoming connections are directed to the server 1, server 2 and then finally server 3 and then the server 1 returns.
Weighted Fair
This technique directs the requests to the load based on the requests of each and the responsiveness of the same (performance) For example, if the servers server 1 is four times faster in servicing requests from the server 2, the administrator places a greater burden of work for the server 1 to server 2.
Combined Cluster High Availability and Load Balancing
This combined solution aims to provide a high performance solution combined with the possibility of not having critical stops. This combined cluster is a perfect solution for ISPs and network applications where continuity of operations is very critical.
Some features of this platform :
- Redirection of requests to node failures reservations for us ;
- Improved quality of service levels for typical network applications ;
- Transparent integration for stand-alone applications and non-clustered together in a single virtual network ;
- Provide a highly scalable architecture framework.
What is a Beowulf Cluster ?
One of the most remarkable technological advances of today, has been the growth of the computational performance of PCs (Personal Computers). The truth is that the PC market is larger than the market for workstations, allowing the decrease in price of a PC, while its performance increases substantially overlapping in many cases, the performance of dedicated workstations.
The Beowulf cluster was envisioned by its developers in order to meet the growing and high processing power in various scientific areas in order to build powerful and affordable cloud computing systems. Of course the constant evolution of processor performance, and has collaborated in approach between PCs and Workstations, decreasing costs of network processors and own technologies and open free operating system like GNU / Linux much research to influence improvement of this new philosophy of high performance processing in clusters.
A key feature of a Beowulf cluster, the software is used, which is of high performance and complimentary on most of their tools, as an example we can mention GNU / Linux and FreeBSD operating systems which are installed on the various tools that enable processing parallel, as is the case of PVM and MPI API’s. This allow to make changes to the Linux operating system to provide it with new features that facilitated the implementation for parallel applications.
Works like Beowulf ?
The system is divided into a controller node called front-end (particularly I call the master node), whose function is to control the cluster, monitoring and distributing tasks, acts as a file server and runs the link between users and the cluster. Large clustered systems can deliver several file servers, the network node manages not to overwhelm the system. The other nodes are referred to as customers or backends (well I call slave nodes), and are solely dedicated to processing tasks sent by the controller node, and there is no need for keyboards and monitors, and possibly even without the use of hard drives (remote) boot, and can be accessed via remote login (telnet or ssh).
No comments:
Post a Comment